Batch Size in Fastai
How to change Batch Size
When using the fast ai Datablock there are a lot of different parameters we can input or change including the batch size. Looking at the documetnation for fast ai heres how the datablock is built:
DataBlock.dataloaders (source, path:str='.', verbose:bool=False,
bs:int=64, shuffle:bool=False,
num_workers:int=None, do_setup:bool=True,
pin_memory=False, timeout=0, batch_size=None,
drop_last=False, indexed=None, n=None,
device=None, persistent_workers=False,
pin_memory_device='', wif=None, before_iter=None,
after_item=None, before_batch=None,
after_batch=None, after_iter=None,
create_batches=None, create_item=None,
create_batch=None, retain=None, get_idxs=None,
sample=None, shuffle_fn=None, do_batch=None)
The code proivded in the ‘00-is-it-a-bird-creating-a-model-from-your-own-data’ uses the following Datablock set up:
datablock = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=[Resize(192, method='squish')],
batch_tfms=aug_transforms(size=224, min_scale=0.75),
)
dls = datablock.dataloaders(path)
We can manipulate this to change the batch size like such:
dls = datablock.dataloaders(path, bs=64)
Note the datablock stays the same but the dls has the extra batchsize parameter input.
Effects of Changing Batch Size
Running on example with gpufrozen on ‘00-is-it-a-bird-creating-a-model-from-your-own-data.ipynb’ Changing the batch size for the dls and then recording results from running the following code:
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(3)
The output of the data looks like this:
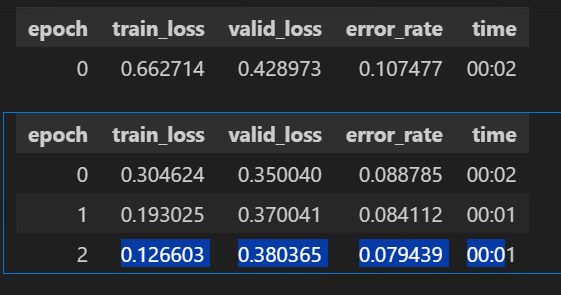
The following table compares the epoch 2 results and total runtime of both vision_learner and fine_tune:
| Batch Size | Run Time (s) | train_loss | valid_loss | error_rate |
|---|---|---|---|---|
| 6 | 37.2 | 0.121135 | 0.156406 | 0.047170 |
| 32 | 15.3 | 0.057337 | 0.208017 | 0.047170 |
| 64 | 14 | 0.066433 | 0.168799 | 0.035377 |
| 128 | 15.7 | 0.104179 | 0.179669 | 0.047170 |
| 256 | 15.4 | 0.151909 | 0.171257 | 0.040094 |
From above the default batch size, 64, is the fastest runtime and the smallest error_rate.
CPU vs GPU
Recalling that with the cpu_frozen it took 11:25 min to run the same test which is 685 seconds So the largest performance difference ratio between gpu and cpu is:
\(GPU : CPU\) \(14 : 685\)
Therefore GPU can be up to 48.9 times faster or just 2% of the runtime of the CPU. This is a significant difference and represents well the desire to use GPU’s instead of CPUs for heavy computational programming tasks like Machine learning.
Why Change the Batch Size
Not every problem will be the same so depending on the type of data you have or the type of algorithm you use, different batch sizes might be more accurate or faster to implement. In the above case, the default was the fastest but that won’t be the case for all scenarios. Imagine if instead of 200 images we had 2000, the batch size then starts to matter a lot more.